
Los data brokers: vampiros de datos que actúan en silencio, especulan con nuestra información y manipulan nuestra vida.
El siguiente articulo fue publicado originalmente por Manuela Battaglini para Transparent Internet consultora Legal, Tecnológica y Ética de Inteligencia Artificial de la cual es socia. Ella es abogada e investigadora y trabaja en Ética Digital (ética de los datos, ética de los algoritmos y ética en la práctica). También es experta en marketing digital estratégico.
 Los mercaderes de los datos
Los mercaderes de los datos
¿Te suenan empresas como Acxiom, Criteo, Equifax, Experian, Oracle, Quantcast, Tapad? Seguro que muchos de ustedes las desconocen, pero ellas a nosotros, nos conocen muy bien.
Son uno de los principales culpables de que grandes organizaciones usen perfiles para tomar decisiones que pueden afectar y cambiar nuestra vida, y la de nuestras familias.
¿Qué ocurre cuando pedimos la información de nuestros perfiles a los mayores vampiros del ecosistema de los datos que nos espían día y noche: los data brokers?
Privacy International presentó en noviembre de 2018 quejas contra estas compañías.
Una pista, si antes de aceptar las cookies se pasean por el listado de los vampiros de datos que ahí residen, localizarán a estos data brokers.
Estas empresas sobre las que Privacy International centró sus quejas formales son data brokers, referencias de crédito (rastrean tu poder adquisitivo), agencias y empresas de publicidad.
Las quejas se basaron en tres puntos:
1. Sobre la emisión de Privacy International de 50 solicitudes de acceso a perfiles.
2. Sobre la base de un análisis de estas políticas de privacidad de la compañía, y
3. Sobre la base de lo que manifiesta ser su actividad de marketing.
Una persona de Privacy International obtuvo respuesta a la solicitud de acceso a Quantcast. Le dieron datos de su historial de navegación vinculado a un identificador único (ID) de cookie. Además, lo que también obtuvo fueron ciertos datos inferidos. ¿Cuáles?
Su género, número de hijos, su educación, sus ingresos. Y lo que también obtuvieron en respuesta a esta solicitud es una gran cantidad de datos de socios de otros data brokers, como MasterCard o Experian.
Los tenemos muy cerca, pero son silenciosos.
Toda esta información estaba ubicada en segmentos que, a su vez, estaban vinculados a identificadores únicos, una ID de cookie, que estaba vinculada a un navegador.
¿Quién pidió el acceso a esta información? Una mujer joven, soltera y sin hijos. Su información inferida en forma de perfil era la de un hombre de 50 años, casado, con hijos y de alto poder adquisitivo. Nada que ver con ella.
Los motivos por los que Privacy International centró su queja fueron, principalmente, dos:
1. Por un lado, hay un abuso recurrente del interés legítimo como base legal para el procesamiento de datos, y
2. La elaboración de perfiles. En muchos casos, estas compañías no han cumplido los principios básicos de protección de datos, transparencia, lealtad, limitación de propósito, minimización de datos, precisión y la necesidad de tener una base legal.
La razón por la que se centran en los data brokers es que el WP29 en su guía 2016/679 (wp251rev.01) sobre las decisiones automatizadas y perfiles, menciona a los data brokers, definiéndolos de esta manera: https://ec.europa.eu/newsroom/article29/document.cfm?action=display&doc_id=49826
WP29 2016/679 (wp251rev.01) sobre las decisiones automatizadas y perfiles
Desde un punto de vista legal, ¿cuáles podrían ser los siguientes pasos?
PRIMERO. Una acción de cumplimiento de la ley que envíe una señal muy clara a las empresas, porque se está aplicando la ley de manera muy diferente. Hay un gran déficit de cumplimiento del RGPD.
SEGUNDO. Necesitamos precedentes que aclaren ambigüedades en la ley. Esperamos que esto sea de interés público y que esto suceda de una manera que proteja a las personas. En definitiva, necesitamos más jurisprudencia, más casos legales.
Privacy International sólo ha arañado la superficie, pues esta queja de solicitudes de acceso se basa en información disponible PÚBLICAMENTE. Esto es lo mínimo que podemos encontrar. Hay que animar a las personas a realizar investigaciones similares y también a presentar quejas.
TERCERO. El alcance y la aplicabilidad del artículo 22 GDPR (sobre el cual nos podemos negar a que nuestros datos sean sometidos a decisiones automatizadas o perfiles). Por ejemplo, Facebook ha dicho que el procesamiento de sus datos no tiene cabida en el artículo 22 GDPR.
La mayoría de la información de los data brokers es vendida, a su vez, a otras empresas para realizar publicidad online. El panorama no es simple. Es un ecosistema MUY COMPLEJO.
Nada mejor que una infografía bien estructurada para hacernos entender mejor de qué estamos hablando.
La fundación polaca Panoptykon realizó esta infografía en la que se ve puede apreciar qué le sucede a cada usuario que está usando cualquier servicio online. Es sobrecogedora:

¿Qué es lo primero que podemos decir sobre esta realidad? Pues que cada uno de los usuarios que usan cualquier servicio de internet tiene un perfil que, a su vez, es una estructura en capas, como vemos en esta infografía.
Primera capa, está compuesta por la información que compartimos. Ejemplos de esto son nombre de usuario, localización, amigos en redes, fotos subidas, metadatos de las fotos, test entregados, huellas digitales, número de tarjeta (ecommerce) o hashtag usados. Sólo como ejemplos.
Segunda capa, lo que el usuario cuentas a través de su comportamiento. La zona geográfica en la que te mueves, anuncios vistos, interacciones que has ignorado, frecuencia de conexión a internet, patrón de compras (rutinas), rastreo del movimiento del ratón (has leído bien). Velocidad con la que escribes en el teclado, sistema operativo, direcciones IP, identificadores únicos, historial de SMS’s, historial de llamada telefónicas, y muchísima más información.
La tercera capa, qué es lo que el algoritmo asume o infiere sobre ti (decisiones automatizadas y perfiles). Afinidad étnica, dónde vives, nuevo puesto de trabajo, nivel de coeficiente intelectual, si estás enfermo o has superado una enfermedad, si quieres tener citas, si eres una comprador/a compulsivo/a, si te has mudado, si eres madre que trabaja en casa, si te gusta la comida basura o la pornografía, si te gusta hacerte la manicura o pedicura… y así, aún muchísimas más inferencias.
Vuelvo a aclarar, esto son SUPOSICIONES del algoritmo.
Hay que tener claro una cosa, esta estructura está formada por datos que NO CONTROLAMOS. Es decir, no tenemos el control para decidir que NO QUEREMOS COMPARTIR los datos de la primera capa.
Cuando aceptamos las políticas de privacidad y cookies, ya es demasiado tarde.
¿Qué datos podemos obtener si exigimos el acceso a nuestros datos? Sólo la primera capa de esta infografía. Y olvídense, por ahora, de obtener datos de la segunda capa, que ya es un análisis de nuestro comportamiento, y aún menos de la tercera capa, que son los datos inferidos.
Y es que, se trata de datos que NUNCA HEMOS PROPORCIONADO, sino que son datos creados por algoritmos basados en las dos primeras capas.
Y podemos estar totalmente en desacuerdo. Pueden ser discriminatorios, o datos muy sensibles que pudieron haberse interpretado después de haber leído contenido online sobre alguna enfermedad, y podemos ser etiquetados en nuestro perfil como persona que padece esa enfermedad.
¿Cuál suele ser la respuesta de estos data brokers cuando queremos ejercer nuestro derecho a acceder a nuestra información? Suelen decir, no sabemos quién eres. Y es que, como usuaria, yo no sé qué ID me corresponde en su base de datos. Concretamente el “Advertising ID”.
Si desconozco este número (que nunca nos lo van a proporcionar) no puedo acceder a mi información, y es muy difícil acceder por cómo está diseñado nuestro sistema.
Hablemos de otra muy buena fuente de información, algo que a mí me fascina y que creo que a muchos de ustedes les va a fascinar también: WIKIDATA. Está hecha con un modelo colaborativo. Entren, echen un vistazo y si pueden añadir info de valor, no lo duden.
¿Para qué sirve wikidata? Proporciona información acerca de las empresas tecnológicas en materia de uso de sus datos. Información como quién es el responsable del tratamiento de los datos, o el email del DPO, y los datos que las empresas están usando.
Hagamos una prueba con UBER. Esta es su página en wikidata, y veamos qué datos de sus usuarios usa:
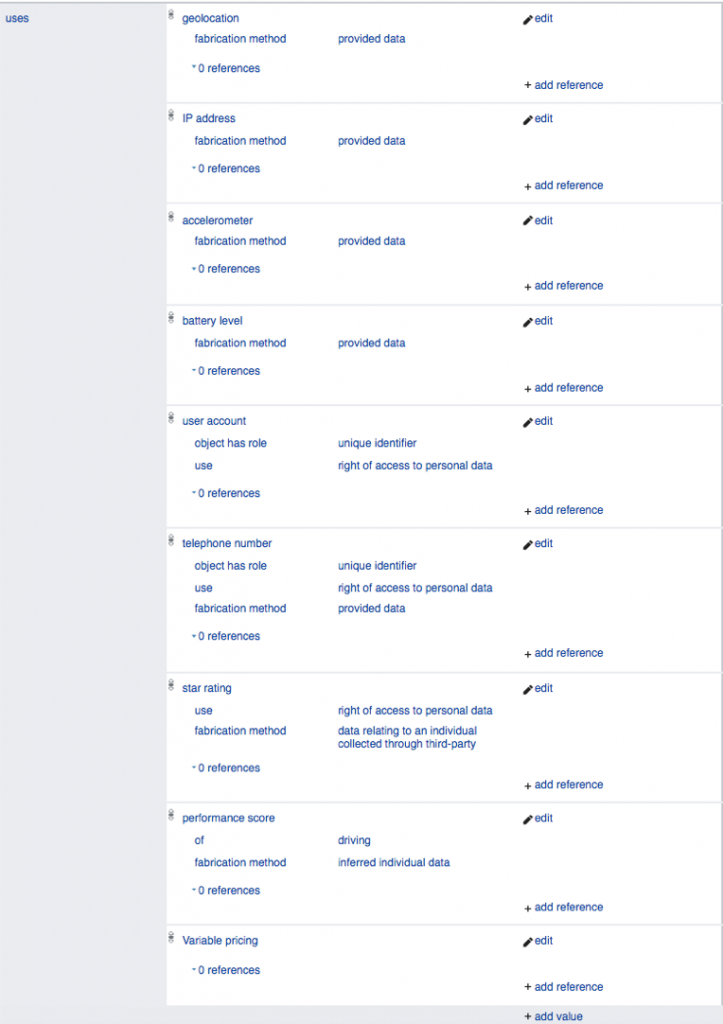
Realizar este mapa de este tipo de empresas es muy útil para otras personas porque pueden trabajar sobre el mismo y reducir los costes de realizar servicios que preserven la privacidad. Como ejemplo de uso.
Ahora, quiero mostrar otra infografía que clasifica la complejidad del marketing digital realizada por Scott Brinker.
La infografía clasifica a 6.242 proveedores únicos de tecnología de marketing en 49 categorías, a su vez, clasificadas en 6 grandes grupos:

Los 6 grandes grupos son:
1. Publicidad y promoción
2. Contenido y Experiencia. La tecnología que permite la experiencia del cliente, interactuando directamente con el usuario final.
3. Social y relaciones
4. Comercio y Ventas
5. Datos
6. Gestión
Y las 5 categorías más importantes:
1. Automatización de ventas e inteligencia (220)
2. Marketing y monitorización de redes sociales (186)
3. Display y publicidad programática (180)
4. Automatización de marketing y gestión de campañas/leads (161)
5. Marketing de contenidos (160)
¿Qué nos dice esta impresionante infografía? La cantidad de proveedores que captan y gestionan nuestra información y que giran alrededor de la publicidad online.
A mi me impresiona el número: 6.242 PROVEEDORES ÚNICOS DE TECNOLOGÍA DE MARKETING.
Pero, ¿cómo es el proceso de recopilación de datos hasta formar un perfil del usuario a través del análisis de su comportamiento (las dos primeras capas de información) en internet?
Cada vez que visitamos una web, o cada vez que usamos una aplicación, cada “empty ad unit”, o cada unidad de publicidad, envía información a otra organización llamada “Ad Exchange” que contiene qué estamos viendo, o qué estamos buscando.
También envían tu localización enviando tu código postal, o las coordenadas de tu GPS. Esto, cada vez que entras en una web o usas una aplicación. ¿A cuántas webs entras al día? ¿cuántas veces usas una aplicación al día? Pues esas son las veces que tu información es enviada.
Toda la industria está gobernada por dos documentos: El IAB, y el otro, por Google.
A través de estas solicitudes, se obtiene información muy concreta para re-identificar a los usuarios y cada movimiento que realizan en internet.
La New Economic Foundation estima que en UK los datos de un usuario medio son enviados ¡164 VECES AL DÍA! a un número indefinido de empresas.

La interconexión de las acciones que realizamos en internet (visitar email, historial de búsquedas, uso de apps, visitas a webs, uso de un servicio online) vincula los datos que de ellas se desprenden y, así, se confecciona una imagen completa del usuario a lo largo del tiempo.
Aquí, juegan un papel muy importante los metadatos y los Identificadores Únicos.
Los metadatos, son información detallada sobre los datos que ayudan a describir con precisión sus propiedades y las relaciones de unos datos con otros.
La Ley de Privacidad del Consumidor de California de 2018 contiene una muy completa definición de los ID: «reconocen a un consumidor, una familia o a un dispositivo vinculado a un consumidor o familia, a lo largo del tiempo y a través de diferentes servicios, incluido un identificador de dispositivo; una dirección de protocolo de Internet; cookies, etiquetas de píxeles, identificadores de anuncios móviles; número de cliente, seudónimo único; números de teléfono u otras formas de identificadores persistentes o probabilísticos que pueden usarse para identificar un consumidor o dispositivo en particular».
Toda esta información, DÍA A DÍA, completa nuestro perfil, segmentado en bases de datos alimentando un sistema de IA que podrá predecir nuestros gustos, nuestra salud, nuestra vida amorosa, nuestra vida sexual, nuestra salud mental, nuestras opiniones políticas, nuestra religión…
Esta información es comercializada y vendida a grandes organizaciones que, a su vez, tomarán decisiones que afectan a nuestra vida seriamente. Información a la que no podemos acceder. Información que es inferida, o asumida.
Así es como se segmentan a las personas por perfiles basados en su comportamiento.
¿Quién nos informó de este maquiavélico plan? NADIE.
¿Por qué los Gobiernos no nos protegen? porque son parte de este maquiavélico plan.
Está en nuestras manos reaccionar.
Como siempre, muchas gracias por leerme. En el siguiente link puedes ver la entrevista a Manuela Battaglini

Hola,
Interesante la nota, pero quizá demasiado técnica para la comprensión de todo el mundo y lo malo, que es lo esencial, no da ningun apoyo para protegerse de esas intrusiones en tu ordenador o teléfono cuando te conectas en internet.
No ha soluciones totales y milagrosas, pero si hay programas libres, idependientes, que están por fuera del mercado de consumo y que en más de una forma te protejen de esas intrusiones, como el buscador lilo.org el navegador de mozilla Firefox, etc.
Además hay ciertas actitudes a tomar en el comportamiento cuando se usa internet para protegerse de algunas forma.
Qué sacan con sólo denunciar algo y en nada ayudan a protegerse de ese algo???
Saludos cordiales.